Conclave is a peer-to-peer, real-time, collaborative text editor built from scratch in JavaScript. Intrigued by collaborative text editors such as Google Docs, we set out to build our own. This case study walks you through our journey from the initial idea to our research of current academic literature and finally to our design and implementation of the final product.
Click to start using Conclave now!
Please note that Conclave works best in Google Chrome

Table of Contents
- What is a text editor?
- What is a real-time collaborative text editor?
- Operational Transformation (OT)
- Conflict-Free Replicated Data Type (CRDT)
- Coding the CRDT
- Limitations of a Central Relay Server
- Peer-to-Peer Architecture
- How will users send messages directly to each other?
- Is WebRTC Secure?
- Version Vector
- Optimizations
- Future Plans
- Our Team
What is a text editor?
First, let’s start by reviewing what we mean by text editor. A text editor is a space where you can insert or delete text characters and then save the resulting text to a file. Each character has a value and a numerical index that determines its position in the document. For example, with the text “HAT”, the first character has a value “H” and a position of 0, “A” has position 1, and “T” has position 2.
A character can be inserted or deleted from the text simply by referencing a positional index. To insert a “C” at the beginning of the text, the operation is insert("C", 0). This insertion results in the remaining positions being shifted (or incremented) by 1. Now to delete the “H”, the operation is delete(1).

What is a real-time collaborative text editor?
One user editing a document seems simple, but what if we want multiple users simultaneously editing the same document? How would that work?
First, we’ll need to provide each user with a local copy of document and allow them to make edits. Remember, we’re aiming for “real-time”; we want users to be able to apply their edits immediately as if they were using a simple text editor.
Note: An example of a non-real-time collaborative editor is a version control system like Git.
Next, we need a way for users to inform other users of edits they made to the document. We’ll introduce a Central Relay Server to facilitate this communication.

Now let’s try inserting a “C” and deleting the “H” as we did with our simple text editor. This time, however, we’ll have one user perform the insertion and the other user perform the deletion. After performing their respective operations, each user will send a message to the other user informing them about the operation.

Oh no! One user has a “HAT” and the other user has a “CAT”. In this particular example, their documents did not converge to the same state. This example demonstrates one of the primary challenges with building a collaborative text editor — getting all users to converge to the same document state.
The reason that the users’ document didn’t converge is because the insert and delete operations were applied in different orders. In mathematical terms, the operations did not commute. For non-mathematicians like ourselves, let’s review what commutativity means. Commutativity occurs when operations applied in different orders produce the same result. For example, addition is commutative because A + B = B + A. Subtraction, however, is not commutative because A - B != B - A.
Let’s try another example where the users simultaneously decide they want to delete the “H” from “HAT” to get a “AT”.

The documents did converge but we have another problem! Both users ended up with an “T” instead of a “AT”, which neither of them wanted. In mathematical terms, the delete operations are not idempotent. What the heck does that mean? Idempotency occurs when repeated operations produce the same result. For example, multiplying by 1 is an idempotent operation. No matter how many times you multiply a number by 1, the result is the same.
With our text editor use case, if both users try to insert the same letter in the same position at the same time, it’s acceptable for the result to be two duplicate characters because it’s easy to find and delete the unnecessary character. When it comes to deletes, however, the character is simply gone without a record of it ever existing; a user would have to remember the value and position of the character in order to insert it back in the document.
Through these examples, we’ve seen that a collaborative text editor is different than a simple text editor. Further, we’ve concluded that when users make concurrent edits to a shared document, the insert and delete operations must commute and the delete operations must be idempotent.
- Commutativity: Concurrent insert and delete operations converge to the same result regardless of the order in which they are applied.
- Idempotency: Repeated delete operations produce the same result.
How can we solve this challenge and build our real-time collaborative text editor?
Operational Transformation (OT)
One possible solution we found is called Operational Transformation (OT). OT is an algorithm that compares concurrent operations and detects if they will cause the documents to not converge. If the answer is yes, the operations are modified (or transformed) before being applied. Let’s see this in action.
Returning to an earlier example, when User1 receives the delete(0) operation from User2, OT realizes that since User1 inserted a new character at position 0, User2’s operation must be transformed to delete(1) before being applied by User1.

Without showing our other example, we can imagine that when a user tries to delete a character that’s already been deleted, OT can easily recognize this and skip the operation. OT solves our challenge by providing a strategy for achieving the commutativity and idempotency we need.
OT was the first popular way to allow for collaborative editing. The first collaborative editors, Google Wave, Etherpad, and Firepad, all used OT. Unfortunately, the verdict from those products is that it’s extremely tough to actually implement.
“Unfortunately, implementing OT sucks. There’s a million algorithms with different tradeoffs, mostly trapped in academic papers. The algorithms are really hard and time consuming to implement correctly. […] Wave took 2 years to write and if we rewrote it today, it would take almost as long to write a second time.”
Joseph Gentle (Google Wave / ShareJS Engineer)
Conflict-Free Replicated Data Type (CRDT)
An alternative strategy was discovered by researchers while trying to strengthen and simplify OT. They called it the Conflict-Free Replicated Data Type (CRDT).
OT is implemented without changing the fundamental structure of a basic text editor. Like a basic editor, OT treats each character as having a value and an absolute position. And to achieve the commutativity and idempotency required by a collaborative text editor, OT relies primarily on an algorithm.
CRDTs take a different approach. Researchers realized that there’s no reason to treat the characters as just having a value and absolute position; they set out to change the underlying data structure of the text editor. Instead, properties are added to each character object that enabled commutativity and idempotency. Using a more complex data structure allows for a much simpler algorithm than OT.
Note: There are many different types of CRDTs with different requirements for different use cases. In this context, a CRDT is primarily a strategy for achieving consistent data between replicas of data without any kind of coordination (e.g. transformation) between the replicas. Since a text document requires the characters to be in a specific order, the type of CRDT that we used is usually categorized as a sequence CRDT.
To use CRDTs specifically for a collaborative text editor, there are a couple critical requirements.
Globally Unique Characters
The 1st requirement is that each character object must be globally unique. This is achieved by assigning Site ID and Site Counter properties whenever a new character is inserted. Since the Site Counter at each site increments whenever inserting or deleting a character, we ensure the global uniqueness of all characters.
With globally unique characters, when a user sends a message to another user to delete a character, it can indicate precisely which character to delete. Let’s see how this changes our earlier example.
Note: For the purpose of simplifying the example, the globally unique ids are just integers. In reality, they’ll be objects with Site ID and Site Counter properties.

With our CRDT, when a user receives a delete operation from another user, it looks for a globally unique character to delete. And if it has already deleted that character, then there’s nothing more it can delete. By ensuring globally unique character objects, we’ve achieved idempotency of delete operations.
Globally Ordered Characters
The 2nd requirement for a collaborative text editor CRDT has to do with the positioning of characters. Since we’re building a text editor, preserving the order of characters within a text document is required. But for a collaborative text editor where each user has their own copy of the document, we must go a step further. We need all the characters to be globally ordered and consistent. That means that when a user inserts a character, it will be placed in the same position on every user’s copy of the shared document.
In our initial text editor example, we noted that when inserting or deleting a character, the positions of surrounding characters would sometimes need to be shifted accordingly. And since characters can be shifted by a user without the other users’ knowledge, we can end up in a situation where insert and delete operations do not commute.
We can avoid this problem and ensure commutativity by using fractional indices as opposed to numerical indices. In the example below, when a user insert an “H” at position 1, they specifically intend to insert an “H” in between “C” and “A”.

Using fractional indices, instead of inserting “H” at position 1, we insert “H” at a position between 0 and 1 (e.g. 0.5). We represent fractional indices in code as a list of integers (or position identifiers). For example, O.5 is represented as [0, 5].

The key is that by using fractional indices to insert characters, we never have to shift the positions of surrounding characters.
Another way to imagine fractional indices is as a tree. As characters are inserted into the document, they can be inserted in between two existing position identifiers at one level of the tree. However, if there is no space between two existing character positions, as demonstrated below, we proceed to the next level of the tree and pick an available position value from there.
Note: There are several academic papers dedicated to how best to “pick an available position”. We implemented an “adaptive allocation strategy for sequence CRDT” called LSEQ.

With globally ordered characters using position identifiers, let’s revisit our example of simultaneous insert and delete operations.
Note: For the purpose of simplifying the example, we’ve omitted the Site ID and Site Counter properties. The globally unique ids here are just the fractional positions. In reality, they’ll be more complex objects.

With our CRDT, we now insert globally unique characters with fractionally indexed positions. The result is that deleting a particular character has absolutely no effect on the insertion of a new character. In other words, our insertion and deletion operations now commute!
If you’re paying close attention, you might ask what happens if two users insert the same character in the same position at the same time. To ensure that these characters are still globally unique, we attach the Site ID to the end of character’s position identifier, and that Site ID is used as a tiebreaker in the event that multiple users inserted the same character in the same position.
Coding the CRDT
With the theory out of the way, how does someone go about actually implementing a CRDT in code?
Web Text Editor
First, we need an actual text editor for our user interface. We first thought of using an HTML textarea as our text editor but soon realized that a textarea element is not able to detect the position at which a letter is inserted or deleted. After some research, we settled on the open-source CodeMirror text editor for it’s ease of use and robust API.
CRDT Structure
For our CRDT data structure, we simply need a globally unique Site ID and a structure to hold our characters objects. To create a globally unique id, we used a library that generates UUIDs. To hold our character objects, we decided on a linear array to make things as simple as possible to start.
class CRDT {
constructor(id) {
this.siteId = id;
this.struct = [];
}
}
Beyond that, our CRDT must handle 4 basic operations:
- Local Insert: User inserts character into their local text editor and sends the operation to all other users.
- Local Delete: User deletes character from their local editor and sends the operation to all other users.
- Remote Insert: User receives a insert operation from another user and inserts it to their local editor.
- Remote Delete: User receives a delete operation from another user and deletes it from their local editor.
Local Insert/Delete
When inserting a character locally, the only information needed is the character value and the editor index at which it is inserted. A new character object will then be created using that information and spliced into the CRDT array. Finally, the new character is returned so it can be sent to the other users.
class CRDT {
// ...
localInsert(value, index) {
const char = this.generateChar(value, index);
this.struct.splice(index, 0, char);
return char;
}
// ...
}
You may wonder what is happening under the hood of the generateChar method. The bulk of the generateChar logic is determining the globally unique fractional index position of the new character. Since each new character’s position is relative to its adjacent characters, the positions of these adjacent characters are used to generate the position of the new character.
generateChar(val, index) {
const posBefore = (this.struct[index - 1] && this.struct[index - 1].position) || [];
const posAfter = (this.struct[index] && this.struct[index].position) || [];
const newPos = this.generatePosBetween(posBefore, posAfter);
// ...
}
As mentioned before, relative positions can be thought of as a tree structure. We took advantage of that structure to create a recursive algorithm that traverses down that tree and dynamically generates a position.
generatePosBetween(pos1, pos2, newPos=[]) {
let id1 = pos1[0];
let id2 = pos2[0];
if (id2.digit - id1.digit > 1) {
let newDigit = this.generateIdBetween(id1.digit, id2.digit);
newPos.push(new Identifier(newDigit, this.siteId));
return newPos;
} else if (id2.digit - id1.digit === 1) {
newPos.push(id1);
return this.generatePosBetween(pos1.slice(1), pos2, newPos);
}
}
Deleting a character from the CRDT is much simpler. All that is needed is the index of the character. That index is used to splice out the character object from our linear array and return it.
localDelete(idx) {
return this.struct.splice(idx, 1)[0];
}
Remote Insert/Delete
Remote operations are where each character object’s relative position comes in handy. When a user receives an operation from another user, it’s up to their CRDT to figure out where to insert it.
To make this as efficient as possible, we implemented a binary search algorithm. When applying a remote delete, the binary search uses the character’s relative position to find it’s index in the array. In the case of remote inserts, the binary search is used to find where it should be inserted in the array.
The return values are passed along to our Editor where the operations are applied in our user’s local CodeMirror text editor.
remoteInsert(char) {
const index = this.findInsertIndex(char);
this.struct.splice(index, 0, char);
return { char: char.value, index: index };
}
remoteDelete(char) {
const index = this.findIndexByPosition(char);
this.struct.splice(index, 1);
return index;
}
With a CRDT in place, our team was able to begin collaborating with one another. Our local operations would get sent to our relay server, which would then broadcast them out to all the other users. Those users would incorporate the changes and any conflicts would be seamlessly resolved due to the commutative and idempotent nature of CRDTs.
Eventual consistency was achieved. HUZZAH!
However, that wasn’t the end of it. While building a CRDT and a simple central relay server were already rather challenging, we wondered how we could make the application even better.
Limitations of a Central Relay Server
The current system architecture relies on the client-server model of communication. It supports multiple users editing a shared document, and between all of our users lies a central server that acts as a relay by forwarding operations to every user in the network of that shared document.
We started with this model because it allowed us to first focus on resolving editing conflicts among users. Now that we had achieved that, could we change our application architecture to a better model? Before we get into what we changed, let’s talk about the limitations of our current central server architecture.
The first limitation is that we currently have an unnecessarily high latency between users. All operations are currently routed through the server, so even if users are sitting right next to each other, they still must communicate with each other through the server.
For example, let’s say we have two users sitting next to each other in Los Angeles while our server is located in New York. Even though the users could be just milliseconds apart, the time it takes to send a message between them is actually 200-300 ms. This latency directly impacts how “real-time” our application feels, and we want to reduce this as much as possible.

The second limitation is that a central server can be costly to scale. As the number of users increases, the amount of work the server must do increases accordingly. To support this, the server would require additional resources, which costs money. As a team creating an open source project, we wanted to minimize the financial cost as much as possible.
The third limitation is that the client-server model requires that users trust the server and anyone that has access to it with their data. That includes the application developers (us in this case), our hosting service, and potentially the government.
And finally, reliance on a central server creates a single point-of-failure. If the server were to go down, all users will immediately lose their ability to collaborate with each other.
Peer-to-Peer Architecture
We can remove these limitations by switching to a peer-to-peer architecture where users send operations directly to each other. In a peer-to-peer system, rather than having one server and many clients, each user (or peer) can act as both a client and a server. This means that instead of relying on a server to relay operations, we can have our users perform that work for free (at least in terms of money). In other words, our users will be responsible for relaying operations to other users they’re connected to.

How will users send messages directly to each other?
To allow nodes to send and receive messages, we used a technology called WebRTC. WebRTC is a protocol that was designed for real-time communication over peer-to-peer connections. It’s primarily intended to support plugin-free audio or video calling but its simplicity makes it perfect for us even though we’re really just sending text messages.
While WebRTC enables our users to talk directly to one another, a small server is required to initiate those peer-to-peer connections in a process called “signaling”.
It’s important to mention that while WebRTC relies on this signaling server, no document content will ever travel through it. It’s simply used to initiate the connection. Once a connection is established, the server is actually no longer necessary.
When a user first opens Conclave, the application establishes a WebSocket connection with the server. Using that connection, the app “registers” with the signaling server, essentially letting it know where it’s located. The server responds by assigning a random, unique Peer ID to the user. The application then uses the assigned Peer ID to create a Sharing Link to display to each user.

The link is unique to each user and is essentially a pointer to a particular user. A user can share their link with anyone, and upon clicking the link, the collaborator will automatically be connected to the user and able to collaborate on the shared document.
To implement signaling and WebRTC messaging, we used a library called PeerJS which took care of a lot of this stuff behind the scenes for us. For example, when a user clicks another user’s sharing link, it’s essentially asking the signaling server to broker a connection between them. The server responds by providing the user with the other user’s IP address, allowing the user to send messages to the other user.
Since most internet users use wireless routers, the public IP address is found using a STUN server. The connecting user then uses the IP address to establish a WebRTC connection, and once established, content can be sent directly between users. In the case that a connection with the STUN server cannot be made and the WebRTC connection fails, a TURN server is used as a backup to send operations between users.

Is WebRTC Secure?
One question we are often asked is Is WebRTC secure and encrypted? The answer is a resounding YES.

According to WebRTC Security:
Encryption is a mandatory feature of WebRTC, and is enforced on all components, including signaling mechanisms. Resultantly, all media streams sent over WebRTC are securely encrypted, enacted through standardised and well-known encryption protocols. The encryption protocol used depends on the channel type; data streams are encrypted using Datagram Transport Layer Security (DTLS) and media streams are encrypted using Secure Real-time Transport Protocol (SRTP).
We can safely say that all of the data that is transferred through Conclave is secure and protected from malicious man-in-the-middle attacks.
Version Vector
WebRTC uses the UDP transport protocol. UDP is a lightweight message protocol that allows it to send messages quickly and without waiting for a response from the other user.
One drawback to UDP is that it does not guarantee in-order packet delivery. That means that our messages may be received in a different order than they were sent. This presents a potential issue. What if a user receives a message to delete a particular character before it’s actually inserted that character?
Let’s say we have 3 peers collaborating on a document. Two of the peers are next to each other while the third is far away. Peer1 types an “A” and sends the operation out to both peers. Since Peer2 is nearby, it quickly receives the operation but decides it doesn’t like it and promptly deletes it.

Now both the insert and delete operations are on their way to Peer 3. But due to the unpredictability of the Internet, the delete operation races past the insert operation.

What happens if the delete operation arrives at Peer3 before the insert operation? We wouldn’t want to apply the delete first because there’d be nothing to delete and the operation would be lost. Later, when the insert is applied, Peer3’s document would look different from the others. We need to find a way to wait to apply the delete operation only after we’ve applied the insert.
To solve the out-of-order messages problem, we built what’s called a Version Vector. It sounds fancy but it’s simply a strategy that tracks which operations we’ve received from each user.
Whenever an operation is sent out, in addition to the character object and whether it’s an insertion or deletion, we also include the character’s Site ID and Site Counter value. The SiteID indicates who originally sent the operation, and the Counter indicates which operation number it is from that particular user.
When a peer receives a delete operation, it’s immediately placed in a Deletion Buffer. If it were an insert, we could just apply it immediately. But with deletes, we have to make sure the character has been inserted first.
After every operation (insert or delete), the deletion buffer is “processed” to check if the characters have been inserted yet. In this example, the character has a SiteID of 1 and Counter of 24.
To perform this check, Peer3 consults its version vector. Since Peer3 has only seen 23 operations from Peer1, the delete operation will remain in the buffer.

After some more time, the insert operation finally arrives at Peer3, and its version vector is updated to reflect that it’s seen 24 operations from Peer1. Since we’ve received a new operation, we again process the deletion buffer. This time, when the deletion operation’s character is compared to the version vector, the delete operation can be removed from the buffer and applied.

The logic described above is contained in the code snippet below. In addition, we’ve added a guard clause that prevents us from applying duplicate operations. In our peer-to-peer network, since peers are tasked with relaying operations, it’s possible that a peer will receive operations that it’s already applied. For every operation, the version vector is used to check if an operation has already been applied, and if so, just skip it with an early return.
handleRemoteOperation(operation) {
if (this.vector.hasBeenApplied(operation.version)) return;
if (operation.type === 'insert') {
this.applyOperation(operation);
} else if (operation.type === 'delete') {
this.buffer.push(operation);
}
this.processDeletionBuffer();
this.broadcast.send(operation);
}
At this point, we’ve described the major components of our system architecture. Within every instance of our application, a custom-built CRDT works together with a Version Vector to make sure our document replicas all converge. The Messenger is responsible for sending and receiving WebRTC messages. And of course, the Editor allows a user to interact with their local copy of the shared document.

So at this point, we now have a peer-to-peer, real-time, collaborative text editor. Our editor allows users to send and receive messages directly to and from one another, resulting in a private and secure way to collaborate on a document.
Optimizations
As our team began to use Conclave, we noticed aspects of the user experience that could be improved. We broke these areas for improvement into three categories:
- CRDT Structure
- Peer-To-Peer Connection Management
- Editor Features
CRDT Structure
As mentioned in Coding the CRDT, we initially structured our CRDT as a linear array of characters. This works well for small documents but becomes inefficient as the number of characters in a document grows. This is primarily due to shifting of the array that’s required when splicing characters into and out of a linear array.
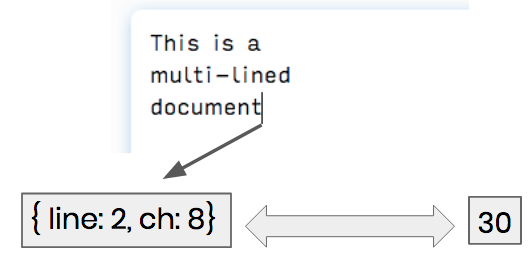
Another issue we ran into is the slow communication between our CodeMirror editor and our CRDT. Whenever a character was inserted into or deleted from the editor, CodeMirror returns a position object that indicates the line and character (i.e. row and column) on which that change was made in the editor.
To use this position object in our linear array CRDT, it needed to be converted into a linear index. This involved retrieving the entire document, splitting it by newline characters, iterating over the lines, and calculating the overall index. The inverse of this process was performed in the case of remote insertions and deletions.
That is a lot of overhead to find a simple index. This led us to wonder how we could structure our CRDT to be more efficient. That’s when we realized the CodeMirror editor itself is structured as a two-dimensional array.

If we could structure our CRDT to match the structure of our text editor, we would eliminate that overhead. It turns out it has a lot of other benefits as well.

Search went from O(log N) — N being the number of characters in the document — to O(log L + log C) — L being the number of lines and C being the number of characters in that line.
We implemented were able to do this by using two binary searches - one to find the correct line and the other to find the character in that line.
In the case of inserting and deleting, the worst-case time complexity for linear arrays is O(N) due to shifting, but it’s only O(C) for the two-dimensional array because only the characters in that line need to shifted.
Finally, we were able to reduce the Find Index complexity from O(N) to O(1) because we can pass the position object that CodeMirror returns directly to the CRDT without any linearization.
To test our theory, we wrote test scripts and recorded how long it took each structure to complete the script. Here are the results:
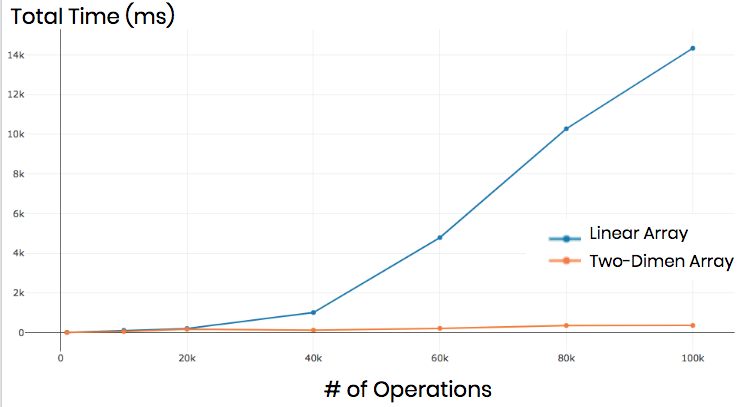
Where it took our original CRDT upwards of 14 seconds to complete about 100 thousand operations, our improved two-dimensional array structure can do it in less than a second. That’s a drastic improvement.
Peer-To-Peer Connection Management
Our major optimizations had to do with how we managed WebRTC connections between users. While WebRTC allows users to connect directly to each other, it’s up to the developer to manage those connections and distribute them through the network.
Note: We define “network” as all the users collaborating on a document, essentially the web of peer-to-peer connections for a particular document. Remember that in this context, the “network” is only made up of the users – there are no servers.
An initial problem we ran into was users getting stranded or cut off from the network. Say we have three users, like in the diagram below.
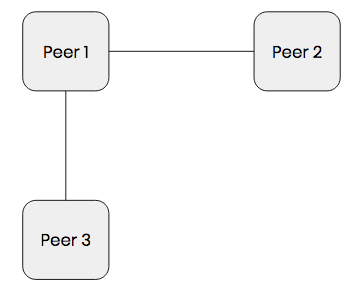
Peer 2 and Peer 3 are connected through Peer 1, who acts as the message relay. But what if Peer 1 leaves?

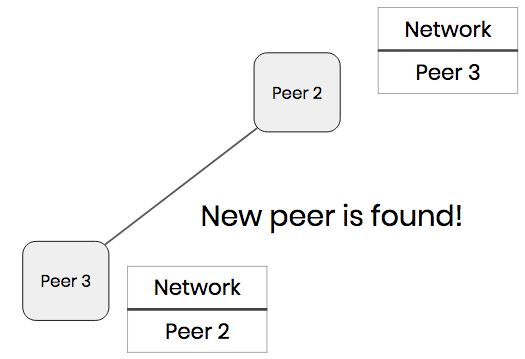
Peer 2 and Peer 3 are now stranded and they can no longer collaborate. To resolve this, we need a way for users to discover each other.
Network List and Peer Discovery
Our solution was to have each peer maintain a list of all the other users in the network. This network list of peers gets updated whenever a user joins and leave the network.
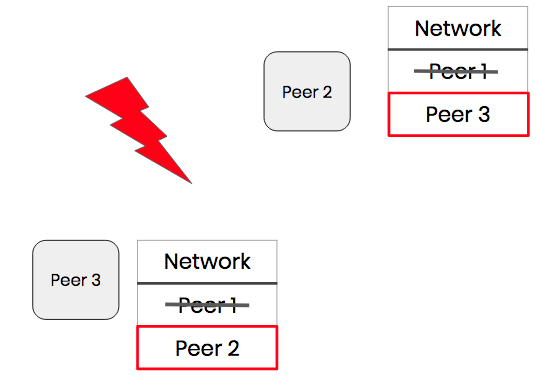
This means that each user is aware of every other user in the network, even if they’re not directly connected to them. So now if a user they are connected to leaves the network, they can pick someone from their network list and connect to them, allowing collaboration to continue.
This is somewhat of a reactive solultion but could we be more proactive? Is it possible to avoid a single point of failure in the first place? After all, that was part of the purpose of creating a peer-to-peer network.
Automatic Network Balancing
In Peer-to-Peer Architecture, we explained how users immediately connect to a user upon clicking that user’s sharing link. The problem is that it’s likely that the first user of a document is going to share their link with several users resulting in that single point-of-failure. Our p2p architecture ends up looking pretty much like the client-server architecture we wanted to move away from.
Our solution was to add an evaluation step before connecting a new user to the network. When a new user attempts to join the document (or network), they send a connection request first.
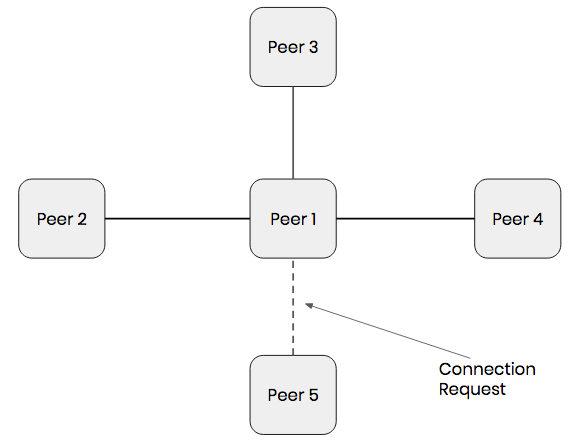
Whoever receives the request will evaluate it to see if they have reached their maximum number of connections. If the answer is yes, they will forward the request to another user in the network. If they haven’t, they will accept the connection and connect back.
evaluateRequest(peerId, siteId) {
if (this.hasReachedMax()) {
this.forwardConnRequest(peerId, siteId);
} else {
this.acceptConnRequest(peerId, siteId);
}
}

What is the maximum number of connections?
To answer that question, we had to calculate the average number of connections we wanted for every user. Since the network can grow and change, a fixed number (O(1)) would not be reliable. At the same time, having each user connected to every person in the network (O(N)) could cause bandwidth issues. We settled on a logarithmic scale (O(log(N))).
However, through testing and trial-and-error, we discovered that this solutions causes unusual bugs when the network is less than 5 users. Therefore, we use 5 as our baseline and when the network grows beyond the point, it transitions to logarithmic growth.
hasReachedMax() {
const partOfNetwork = Math.ceil(Math.log(this.network.length));
const tooManyConns = this.connections.length > Math.max(partOfNetwork, 5);
return tooManyConns;
}
This is far from a perfect solution. While we did reduce the chances of a single point of failure, it doesn’t prevent bottlenecks from being formed.
Editor Features
While our in-browser editor technically worked, it wasn’t very user-friendly at all. To improve its usability, we implemented a few critical features: remote cursors, video chat, and upload/download.
Remote Cursors
Having several people edit a document at the same time can be a chaotic experience. It becomes even more hectic when you don’t know who else is typing and where.
That is the situation we ran into. Without a way to identify another person on the page, users would end up writing over each other and turning the real-time collaboration experience into a headache. We solved this problem with remote cursors.
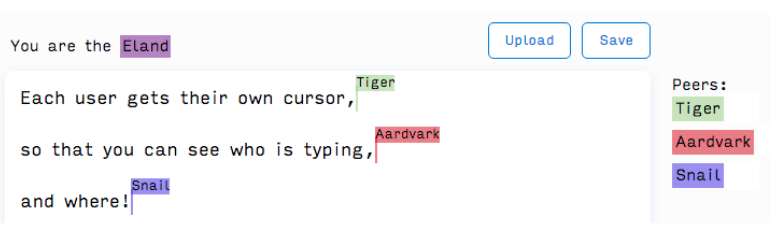
Each user is represented by a cursor with a unique color/animal combination that identifies the user and their cursor’s location in the document.
Implementing remote cursors in a decentralized environment isn’t trivial. Without a central database to keep track of each user’s cursor, how do we keep the remote cursors combinations consistent among all users and prevent users from ending up with the same color/animal combinations?
To address the consistency issue, we created a simple modulo hashing algorithm that reduces each user’s unique Site ID into an index that maps to a color/animal combination.
addRemoteCursor() {
// ...
const color = generateItemFromHash(this.siteId, CSS_COLORS);
const name = generateItemFromHash(this.siteId, ANIMALS);
// ...
}
function generateItemFromHash(siteId, collection) {
const hashIdx = hashAlgo(siteId, collection);
return collection[hashIdx];
}
function hashAlgo(input, collection) {
const filteredNum = input.toLowerCase().replace(/[a-z\-]/g, '');
return Math.floor(filteredNum * 13) % collection.length;
}
With 221 possible animals and 210 possible colors, it’s unlikely users will ever have the same color/animal combo.
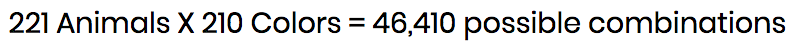
Video Chat
Since we’re already using WebRTC to send text messages between users, we realized it’d be relatively simple to add video chat as well.

To place a call, users click on any animal in their list of peers. The receiving user is alerted and can answer the call by clicking your animal in their list of peers. A video modal pops up on both screens and can be dragged around the screen to a more convenient location. Clicking the x ends the call and all WebRTC media channels are closed. At the moment, a user can only be on a video call with one other user at a time.
videoCall(id, ms) {
navigator.mediaDevices.getUserMedia({audio: true, video: true})
.then(ms => {
if (!currentStream) {
const callObj = peer.call(id, ms);
callObj.on('stream', stream => {
streamVideo(stream, callObj);
callObj.on('close', () => {
currentStream.localStream.getTracks().forEach(track => track.stop());
currentStream = null;
});
});
}
});
}
Note: In order for WebRTC to detect the media devices (camera and speaker) of any computer trying to join a video call, the initial signaling must be conducted over HTTPS.
Download
Since we eliminated the central relay server, there is no server to store a user’s documents. We needed to provide a way for users to save what they were working on. Adding a download button was simple. Any user can click the Download button to save the current document text to their computer.
downloadButton.onclick = () => {
const text = editor.value();
const blob = new Blob([text], { type:"text/plain" });
const link = document.createElement("a");
link.style.display = "none";
link.download = "Conclave-"+Date.now();
link.href = window.URL.createObjectURL(blob);
link.onclick = e => document.body.removeChild(e.target);
document.body.appendChild(link);
link.click();
}
When the download button is clicked, the text in the editor is converted to a plain text blob object. An invisible link is created with its href property set to this blob as a URL and its download property set to the filename. The link is added to the DOM, clicked, and then removed.
Upload
In a similar vein, what if someone wants to continue editing a previously downloaded file or some existing document? To support this, we added the ability to upload a file.
We used JavaScript’s built-in FileReader to read the contents of the file selected for upload. The text is inserted into the user’s CRDT and then their editor text is replaced entirely by the data in the CRDT. Updating the editor is fast but insertion into the data structure happens one character at a time, so large documents can take a while. This is an area for future improvement.
fileSelect.onchange = () => {
const file = document.querySelector("#file").files[0];
const fileReader = new FileReader();
fileReader.onload = (e) => {
const fileText = e.target.result;
localInsert(fileText, { line: 0, ch: 0 });
replaceText(crdt.toText());
}
fileReader.readAsText(file, "UTF-8");
}
To prevent massive erasure and potential confusion, only a user who starts a new document will have the option to upload. Users joining a collaboration session will not see the upload button.
Future Plans
Better Connection Distribution
The first thing to further improve would be the connection distribution for users in the network. A possibility we are entertaining is to have new users connect to more than one user initially. This will prevent collaborators from becoming stranded if one of their connections drops and they are forced to find a new user to connect to.
Mass Insertions/Deletions
Currently, our CRDT can only insert and delete one character at a time. Being able to add or remove chunks of text at once will drastically improve overhead and improve the efficiency of large cuts and pastes (as well as uploads).
Automated P2P Network Testing
Testing the p2p nature of Conclave is difficult. The majority of our bugs were found through manual testing, which is inefficient and risky. In order to simulate real world latency scenarios, we would need to buy servers in data centers across the country and world. It’s feasible but we don’t currently have the resources to achieve such a feat.
Embeddable Browser Editor
Finally, you may have heard of the recent release of GitHub’s Teletype. We were really excited about the news because it also utilizes WebRTC and CRDTs. Furthermore, it gave us the idea to create our own embeddable collaborative editor for the browser. It would not be too difficult to pull off so keep an eye out for that!
Our Team
We hope you enjoyed reading about our journey as much as we enjoyed the journey itself! We are all available for new opportunities, so please feel free to reach out!


